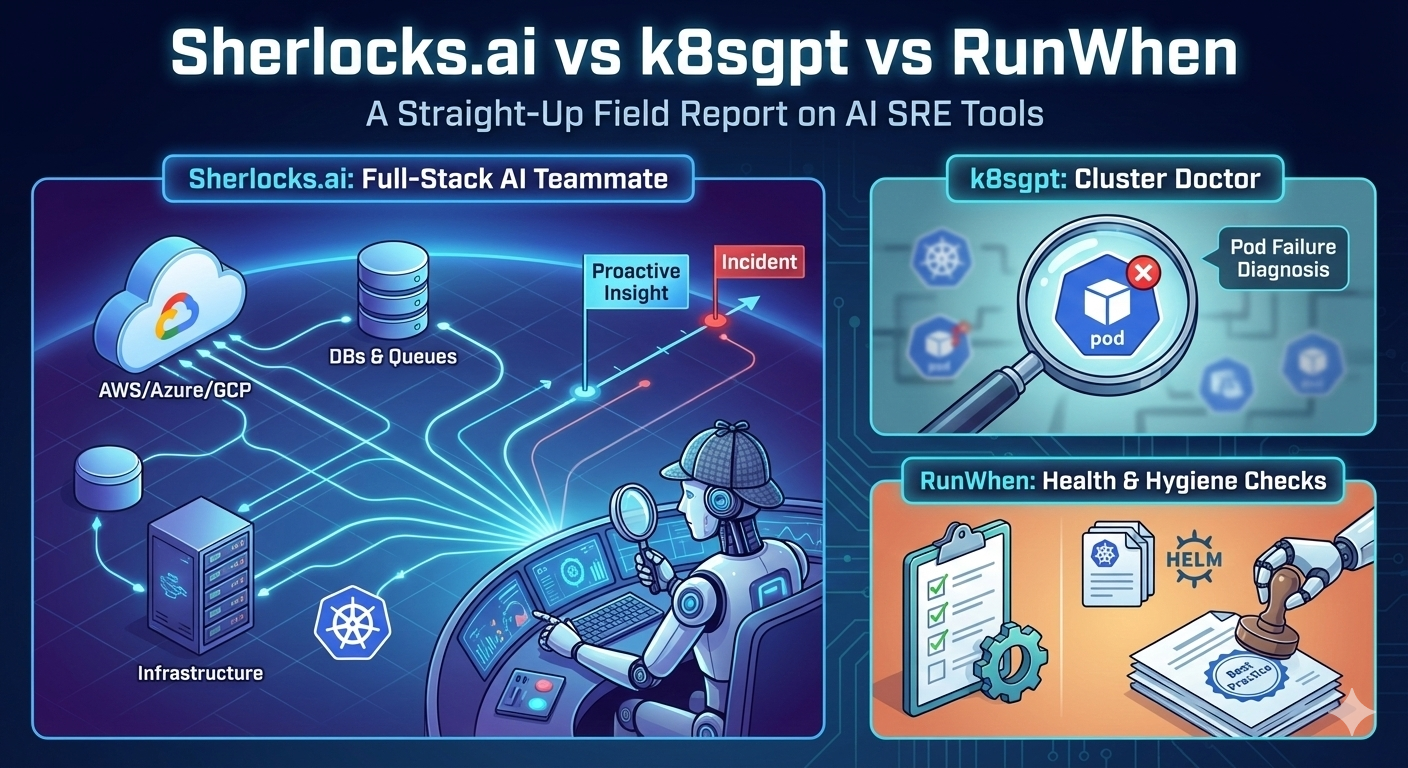
1. What each tool actually watches
| Tool | Watches | Misses |
|---|
| Sherlocks.ai | Metrics, logs, traces, change events, tickets, cloud services, databases, queues and Kubernetes | |
| k8sgpt | Kubernetes objects & events | Everything outside the cluster |
| RunWhen | K8s manifests and upgrade state | App-level signals and multi-cloud context |
The short version: k8sgpt and RunWhen know a lot about what’s inside your cluster. Sherlocks looks at the whole system cloud services, queues, the noisy neighbour DB, you name it. You can check how Sherlocks compares to enterprise observability platforms like PagerDuty, New Relic, and Datadog.
2. What happens when something breaks
Sherlocks.ai
- Builds a timeline from every signal it can find
- Offers a root-cause hypothesis in plain English
- Suggests (or auto-executes) a fix and leaves an audit trail
k8sgpt
- Explains what’s wrong with a pod or deployment
- Spits out one-off commands to try next (for translating those commands into natural language, check out kubectl-ai for natural language commands)
- Stops at the edge of the cluster
RunWhen
- Runs best-practice rules and upgrade playbooks
- Great for hygiene, less so for surprise outages
3. How you interact with each tool
Sherlocks drops into your Slack or Zoom bridge, answers follow-ups, tracks action items and drafts the RCA before the smoke clears.
k8sgpt and RunWhen live in a CLI or their own dashboard you run them, read the output, and take it from there.
4. Proactive vs. reactive
Sherlocks never sleeps. It scans telemetry around the clock and raises a flag before the pager barks.
k8sgpt and RunWhen kick in after you ask them to look or on a scheduled scan.
5. Plug-and-play reality check
| Feature | Sherlocks.ai | k8sgpt | RunWhen |
|---|
| Datadog / CloudWatch / Grafana integration | ✔️ | ❌ | ❌ |
| Hybrid / on-prem deploy | ✔️ | ✔️ (binary) | ⭕ |
| SOC 2 roadmap | In progress | Community OSS | In progress |
| Human-in-loop approvals | ✔️ | N/A | Rule-based |
The takeaway
- k8sgpt is a sharp cluster doctor excellent when your YAML goes sideways.
- RunWhen automates the routine health checks and upgrades we all forget.
- Sherlocks.ai plays the role of full-stack SRE teammate. It sees the whole system, reasons across services, and helps drive the incident to closure whether that means a kubectl rollback, a database failover or a quick note in PagerDuty. For a comprehensive AI SRE tool comparison beyond Kubernetes-focused tools, see our 2026 landscape analysis.
If that sounds useful, let’s chat. I’m always happy to walk through a live demo on your own stack.
Stay stable, ship faster. 🚀