Quick Summary: Top 15 AI SRE Tools in 2026
AI SRE has crossed the tipping point. Teams using AI-assisted incident response are reporting 40 to 70% reductions in MTTR, and the AIOps market is projected to grow from $14.6B today to $36B by 2030. The question is no longer whether to adopt AI SRE, it is which tool fits your stack. If cutting recovery time is your primary goal, start with our step-by-step guide on how to reduce MTTR.
We evaluated 15 platforms across causal reasoning depth, auto-remediation maturity, Kubernetes support, pricing transparency, and real-world integration complexity. Here is the short version:
| If you need... | Best pick |
|---|---|
| Institutional memory and siloed knowledge fix | Sherlocks AI |
| Autonomous remediation at Fortune 500 scale | Resolve.ai |
| Causal RCA for complex microservice systems | Traversal |
| Safety net across hybrid and multi-cloud stacks | Neubird (Hawkeye) |
| Data pipeline and startup-scale investigation | Deductive.ai |
| AI investigation inside Datadog, zero context switch | Datadog Bits AI |
| Full-stack correlation and native AI auto-remediation | Middleware OpsAI |
| Full incident lifecycle automation | Rootly AI SRE |
| OpenTelemetry-native AI with zero vendor lock-in | Agent0 (Dash0) |
| Live runtime evidence for AI-generated code failures | Lightrun AI SRE |
| CI/CD-native incident response | Harness AI SRE |
| AWS-native AI SRE with no third-party tooling | AWS DevOps Agent |
| Kubernetes-specialist with autonomous self-healing | Komodor (Klaudia AI) |
| Zero-instrumentation Kubernetes AI SRE | Metoro |
| Enterprise full-stack observability and SRE | Dynatrace (Davis AI) |
The chaotic nature of SRE work, juggling alerts, outages, and mounting complexity, is exactly what this new generation of tools is built to address. We have moved beyond collecting metrics and into the age of Agentic SRE. For the complete SRE and DevOps toolchain, see our Best SRE and DevOps Tools for 2026 guide.
Why are human SREs not enough anymore?
Modern systems are easier to build than to operate. Microservices, distributed architectures, and Kubernetes have made that gap wider every year. Changes ship faster, reviews are lighter, and a bad deployment can take down more than it used to. At some point, human-only incident response just stops keeping up.
What is AI SRE in 2026?
AI SRE uses LLM-powered reasoning to detect, investigate, and resolve production issues. Instead of surfacing isolated alerts, these tools analyze signals across your entire stack and tell you what broke, why it broke, and what to do next. As Forrester reports on AIOps transformation, AI-powered operational intelligence can reduce incidents by 20-30% through predictive analysis and automated remediation. For a deeper dive into what AI SRE addresses and why it's possible now, check out our foundational guide.
For a full explanation of what AI SRE is and how it works, see What Is AI SRE.
Why 2026 is the Tipping Point ?
The short answer is LLMs. Before them, building systems with memory, retrieval, and multi-agent coordination was slow, expensive, and rarely worth it. That changed fast. Google's own SRE teams now use Gemini CLI to handle incident response and postmortem generation, and every major cloud provider has shipped a native AI SRE product in the last 12 months.
Key Capabilities to Look for in 2026
If you're assessing a tool today, don't ask about "data ingestion", that's already solved. As Gartner defines AIOps, the focus has shifted from data collection to actionable intelligence that combines big data and machine learning for autonomous operations. Look for these four "Agentic" benchmarks:
Does the tool wait for a threshold to break, or does it independently run parallel hypothesis tests across deployments, infrastructure, and service dependencies?
The system must differentiate between a symptom (high CPU) and an underlying cause (a specific code path or resource lock).
A 2026-ready tool must consider your Slack history, post-mortems, and Jira tickets. If a similar incident occurred six months ago, the AI should bring up that fix right away.
Full autonomy can be risky. The tool should explain its reasoning and require explicit human approval for significant actions like cluster scaling or rollbacks.
AI SRE in 2026 can broadly be approached in three ways: AI-native platforms that offer end-to-end incident automation, cloud-native solutions like AWS that embed AI directly into existing infrastructure, and open-source stacks that combine observability tools with custom AI workflows. The tools below cover all three. Which one fits depends mostly on where your infrastructure already lives.
The Top AI SRE Tools for 2026
To help you navigate the options, we've grouped these tools as you're not just buying a license; you're hiring a digital teammate. If your primary goal is cutting incident recovery time, see our guide on how to reduce MTTR with AI tools.
AI-Native SRE
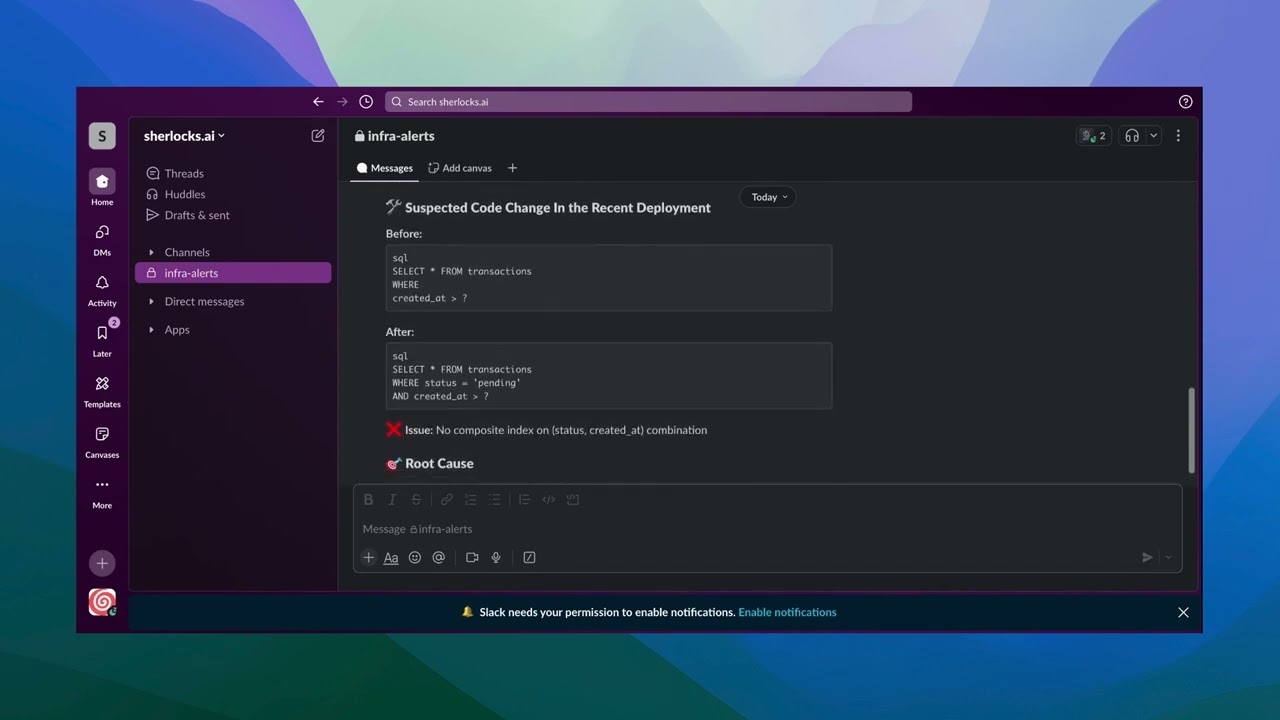
 1. Sherlocks AI
1. Sherlocks AI
Sherlocks AI builds an awareness graph that links telemetry with historical incidents and operational context. This helps teams retain and reuse knowledge that might otherwise be lost in chat threads or post-mortems.
Teams suffering from "Siloed Knowledge" where only a few senior engineers know how to fix recurring issues.
Free trial. Starting from $1500 / month. Custom pricing is also available.
Pros
- Builds a persistent awareness graph linking live telemetry with past incidents and Slack history, so repeat incidents get solved faster over time
- Lightweight setup: Watson agent deploys inside your VPC in minutes and raw telemetry never leaves your network (SOC 2 Type 2)
- 16+ domain-specialized agents (Database Sherlock, Kubernetes Sherlock, and more) run in parallel rather than one generalist LLM trying to cover everything
Cons
- Starting at $1,500/month, it is not accessible for solo engineers or very early-stage teams
- Value builds as it learns your environment, so teams expecting instant RCA on day one may feel underwhelmed in the first week
- Institutional memory works best for teams with good Slack hygiene and postmortem discipline; messier teams get less out of it
 2. Resolve.ai
2. Resolve.ai
Generates remediation suggestions and proposed fixes, with human approval required for execution.
Organizations looking to automate "Level 1" support and eliminate repetitive on-call toil.
$1,000,000/ 12 months . Custom pricing is also available.

Pros
- Runs parallel investigations across code, infrastructure, and telemetry simultaneously rather than sequentially
- Proven at enterprise scale: Coinbase (73% faster RCA), DoorDash (87% faster investigation), and Salesforce are verified customers
- Human-in-the-loop approval gates before any automated action, which matters for teams nervous about autonomous changes in production
Cons
- At $1M+/year, there is no mid-market entry point. This is purely a Fortune 500 tool
- Heavy upfront integration work required across code repos, CI/CD, and telemetry before delivering meaningful value
- Security and data handling documentation is thin publicly. You will not get clarity until you are deep in the procurement process
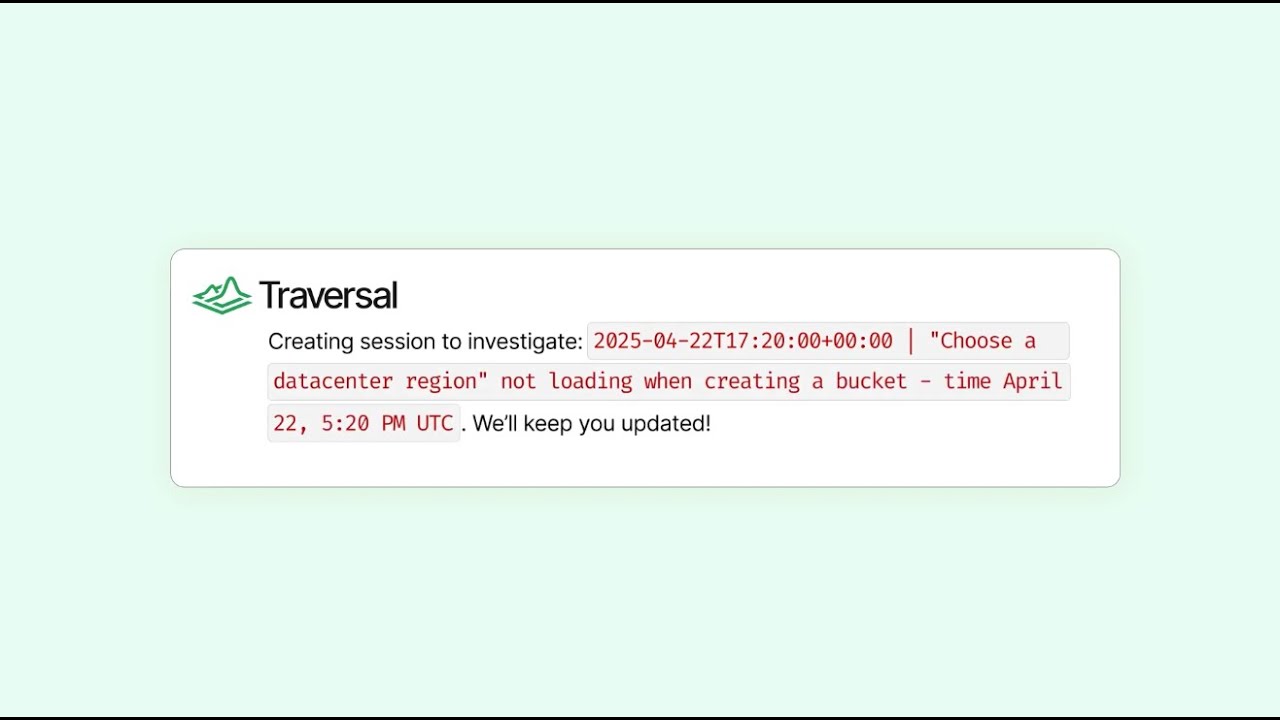
 3. Traversal
3. Traversal
Focuses on rapid, causal root cause analysis that connects user-facing symptoms to upstream system failures.
Large-scale enterprises with massive microservice meshes where "The Butterfly Effect" makes troubleshooting impossible.
Not Available
Pros
- Causal reasoning engine built specifically for distributed systems, tracing failures across dependency chains without new instrumentation
- Non-intrusive by design: no additional agents needed in your production environment
- Particularly strong at cascading failure scenarios where a small upstream change causes downstream chaos that is impossible to trace manually
Cons
- Pricing is completely undisclosed, so you cannot assess cost-to-value without going through a full sales cycle
- Scope is narrower than full-lifecycle platforms: excellent at RCA but does not cover coordination, runbooks, or postmortems
- Less useful for teams running simpler monolithic or legacy architectures where deep causal traversal is overkill
 4. Neubird (Hawkeye)
4. Neubird (Hawkeye)
Strong emphasis on collaborating with existing monitoring stacks rather than replacing them, especially in hybrid and multi-cloud setups.
Traditional enterprises moving to the cloud that need a "Safety Net" across hybrid stacks (AWS + On-Prem).
Free trial. Starting from $15/ investigation. Custom pricing is also available.

Pros
- Built for hybrid and multi-cloud environments, working alongside your existing monitoring stack rather than replacing it
- Per-investigation pricing ($15/investigation) makes it easy to trial without a large upfront commitment
- Strong fit for enterprises mid-cloud migration who cannot rip and replace existing tooling overnight
Cons
- Per-investigation pricing scales poorly at high volume. 500 investigations/month is $7,500 before any platform fees
- Less differentiated in purely cloud-native environments where purpose-built AI SRE tools offer deeper reasoning
- Fewer public case studies compared to Datadog, Rootly, or Resolve.ai, making it harder to benchmark expected outcomes before buying
 5. Deductive.ai
5. Deductive.ai
Uses knowledge graphs to link application logic with real-time system behavior and clarify why failures happen.
Data-heavy engineering teams and fast-moving startups where manual triage doesn't scale.
Not Available

Pros
- Knowledge graph approach links application logic to real-time system behavior, going beyond metric correlation to explain the actual why
- Well-suited to data pipeline failures, which most SRE tools handle poorly since they are optimized for web service incidents
- Low configuration overhead makes it a good fit for fast-moving teams where manual triage is already the bottleneck
Cons
- No public pricing means evaluation requires direct vendor engagement, adding friction for teams doing a quick shortlist
- Relatively early stage compared to Datadog or Rootly, with less proven track record at 1,000+ microservice scale
- Integration ecosystem is not well-documented publicly, so teams with niche observability stacks may hit gaps
 6. Lightrun AI SRE
6. Lightrun AI SRE
Launched in February 2026 and recognized in the 2026 Gartner Market Guide for AI SRE Tooling, Lightrun takes a fundamentally different approach to the category. While most AI SRE tools work with telemetry that was already captured, Lightrun's Runtime Context engine generates missing evidence on demand by interacting directly with live running systems, without requiring redeployments.
Lightrun can safely add logs, traces, and snapshots to production environments in real time through a patented Sandbox. Teams can prove root causes against live execution data rather than guessing from incomplete telemetry.
Teams dealing with unknown unknowns, incidents where logs are missing, traces are incomplete, or the issue was introduced by AI-generated code that behaves unpredictably at runtime.
Not available

Pros
- Only tool in this list that generates new evidence dynamically from live systems, rather than relying on what telemetry you already have
- Covers the full SDLC from pre-production through live incidents, bridging the gap between dev and ops that most SRE tools ignore
- Purpose-built for environments where AI-generated code is shipping faster than observability can keep up
Cons
- No public pricing tiers, making it hard to assess fit without going through a sales process
- The live instrumentation model requires trusting Lightrun's Sandbox security guarantees in production, which some security-conscious teams may scrutinize closely
- Newer to the AI SRE category than Datadog or Rootly, with a shorter track record at scale despite strong early customer logos
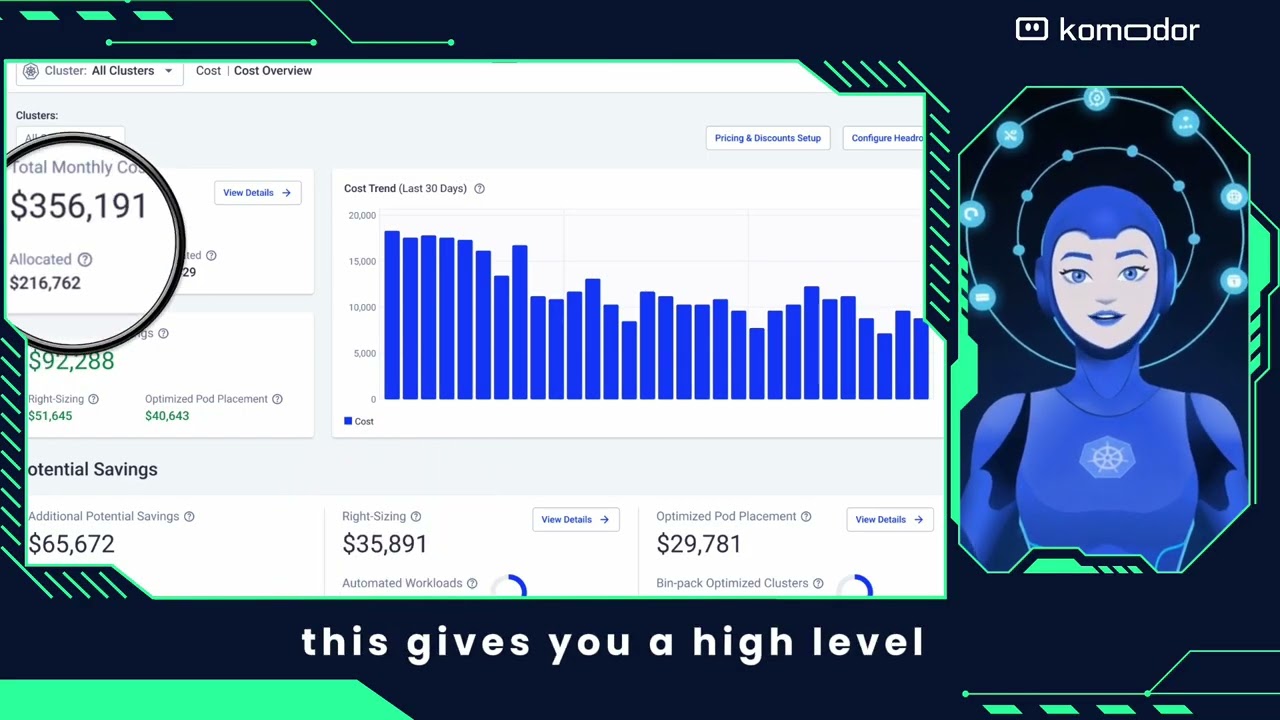
 7. Komodor (Klaudia AI)
7. Komodor (Klaudia AI)
Komodor is the most Kubernetes-focused platform on this list. Its Klaudia AI agent is trained on telemetry from thousands of production Kubernetes environments and achieves 95% accuracy across real-world incident resolution. The platform tripled its ARR after launching Klaudia and was named a Representative Vendor in the 2026 Gartner Market Guide for AI SRE Tooling.
Klaudia is a Kubernetes domain specialist, trained specifically on pod crashes, failed rollouts, autoscaler friction, misconfigurations, and cascading failures in cloud-native environments. It also folds cost optimization into the SRE loop, treating cloud spend efficiency as a reliability outcome.
Platform and SRE teams running large-scale Kubernetes environments who need both autonomous incident resolution and cost optimization in one platform.
Custom pricing
Pros
- Best-in-class Kubernetes domain expertise, trained on thousands of real production environments rather than general software engineering knowledge
- Autonomous self-healing with configurable guardrails lets teams choose their comfort level with automation, from fully supervised to fully autonomous
- Uniquely combines reliability and cost optimization: dynamic right-sizing, intelligent pod scheduling, and workload migration are all handled by the same AI agent
Cons
- Scope is intentionally narrow. Teams running non-Kubernetes or mixed infrastructure will find limited value outside the cloud-native stack
- Pricing is not publicly available, adding friction for smaller teams trying to evaluate fit before engaging sales
- Kubernetes-only focus means it does not address the coordination, communication, or postmortem phases of incident management that broader platforms cover
Observability with AI SRE
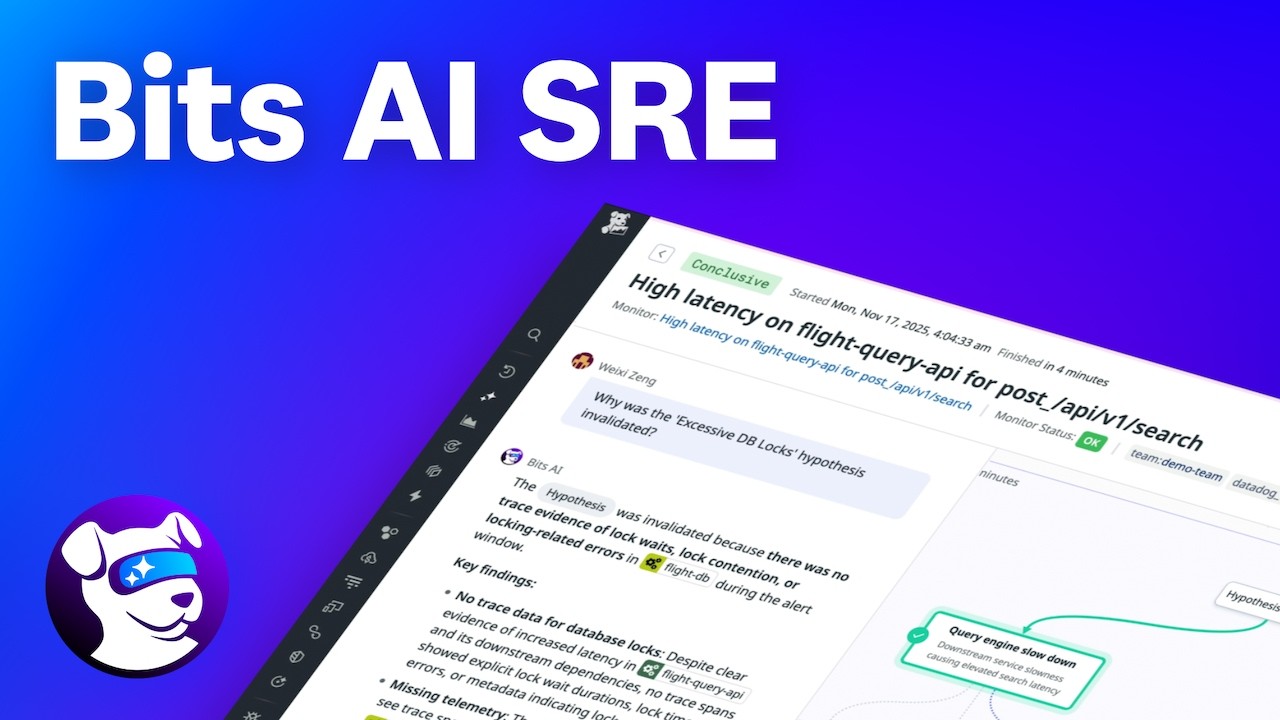
 8. Datadog (Bits AI SRE)
8. Datadog (Bits AI SRE)
Offers direct, zero-context-switch access to AI-driven investigation within one of the most widely used observability platforms.
Teams already fully invested in the Datadog ecosystem who want "Zero-Switch" AI power.
Free Trial. $500 per 20 investigations/ month
Pros
- AI investigation lives inside the same platform as your metrics, logs, and traces, so there is zero context switching or new tooling to learn
- Enterprise-grade reliability, compliance certifications, and global support infrastructure that most newer entrants cannot match
- Best-in-class high-cardinality data handling, built to reason across billions of unique data points without performance degradation
Cons
- Only valuable if you are already deeply invested in Datadog. Teams on Grafana, New Relic, or mixed stacks get little benefit
- $500 per 20 investigations can escalate quickly for high-incident-volume teams, making monthly costs hard to predict
- The AI layer is an add-on to an observability platform, not a purpose-built investigation engine. Depth of causal inference lags behind Sherlocks AI, Traversal, or Resolve.ai
 9. Metoro
9. Metoro
Metoro is a Kubernetes-native AI SRE platform that uses eBPF instrumentation to collect complete cluster context at the kernel level, no code changes, no container restarts, operational in under a minute.
Most AI SRE tools inherit whatever telemetry your team already configured. Metoro skips that dependency entirely. Its eBPF agent captures every call and operation across the cluster by default, giving the AI clean, complete context before investigation starts rather than noisy, incomplete signals after the fact.
Kubernetes teams that want strong AI-assisted RCA and deployment verification without adding instrumentation overhead to an already complex stack.
Free tier (1 cluster, 2 nodes). $20/node/month on the Scale plan. Enterprise pricing available.

Pros
- eBPF collection gives the AI full cluster visibility without touching application code or restarting containers
- Covers detection, RCA, alert investigation, and deployment verification in one platform
- Most accessible pricing on this list, free to start, $20/node/month for production, no hidden fees
Cons
- Kubernetes-only; no value for teams running non-containerized or mixed infrastructure
- Uses OpenAI models for AI features, teams with strict data residency requirements should evaluate the on-prem option before committing
- Earlier stage than Datadog or Komodor, with fewer published enterprise case studies
 10. Middleware OpsAI
10. Middleware OpsAI
Combines full-stack correlation across backend, frontend, and telemetry down to the line of code with a configurable autonomy dial. Teams can choose Auto RCA mode (which proposes a fix as a PR) or Auto Fix mode (which applies the fix directly).
Teams willing to adopt a unified observability stack in exchange for deep, native AI remediation capabilities.
Usage-based, free 14-day trial (2M OpsAI tokens, no credit card).

Pros
- First-party access to the underlying observability stack provides deeper context than agent-layer tools sitting on third-party APIs
- Configurable autonomy gives teams control, offering both direct Auto Fix and PR-generating Auto RCA
- PR generation runs securely via GitHub MCP integration with file-scoped reads and zero source-code retention
Cons
- Reached general availability in May 2026, making it one of the newest entrants with a limited enterprise-scale track record
- Automated code-fix delivery runs through GitHub MCP only; GitLab and Bitbucket teams get the RCA loop but not auto-fix
- Usage-based pricing is hard to forecast at high incident volumes; model expected investigation frequency before committing
 11. Agent0 (by Dash0)
11. Agent0 (by Dash0)
Agent0 is 100% OpenTelemetry native. It provides extreme transparency by showing the exact signals, reasoning steps, and tools used by the agents. Because it uses open standards, all generated queries (PromQL) and dashboards remain portable and don't create vendor lock-in.
Teams that want deeply contextual, observable-native AI assistance that reduces MTTR while being transparent about reasoning and tool usage.
Free trial available. Usage-based. Base subscription starts at $50 / month.

Pros
- 100% OpenTelemetry native: all queries, dashboards, and outputs use open standards with zero vendor lock-in on your telemetry data
- Full transparency on reasoning, showing the exact signals, logic steps, and tools used to reach any conclusion
- $50/month base subscription is the most accessible entry point on this list for teams wanting to trial a capable AI SRE agent
Cons
- Tightly coupled to the Dash0 platform. Teams not already on Dash0 face a platform migration decision before getting value from Agent0
- Newer to market than Datadog or Rootly, with fewer enterprise-scale case studies and less of a proven track record in high-stakes production
- Usage-based pricing above the base tier is not fully transparent publicly, making costs at scale hard to forecast
 12. Dynatrace (Davis AI)
12. Dynatrace (Davis AI)
Dynatrace is the enterprise observability incumbent with the longest AI pedigree on this list. Davis AI has been in production since 2017 and has evolved into a hypermodal system combining predictive AI, causal AI, and generative AI (Davis CoPilot) in one unified platform. With nearly $1.9B in ARR and customers like Vodafone, United Airlines, and Western Union, it is the default choice for large enterprises.
Davis AI uses Dynatrace's Smartscape real-time topology map alongside its Grail data lakehouse to perform deterministic causal analysis rather than probabilistic guessing. It can identify the precise root cause of an incident, including blast radius and dependency chain.
Large enterprises operating complex, multi-cloud or hybrid environments who want a single platform covering observability, security, and AI-assisted SRE under one roof with enterprise-grade compliance built in.
Starting from $58/month per 8 GiB host

Pros
- Longest proven track record of any AI in this category: Davis AI has been in production since 2017, giving it a depth of causal reasoning that newer entrants are still building toward
- Hypermodal AI combining predictive, causal, and generative capabilities means teams get forecasting, RCA, and natural language automation without stitching tools together
- Enterprise-grade security, compliance, and global support infrastructure that most newer AI SRE startups cannot match
Cons
- Platform complexity is significant: getting full value from Davis AI requires deep investment in Dynatrace's broader ecosystem, which is not a lightweight decision
- Per-host pricing can escalate sharply in large environments and is hard to forecast without working through Dynatrace's sales process
- Breadth of the platform can slow adoption for teams that want focused AI incident investigation rather than a full observability overhaul
Incident Management with AI SRE
 13. Rootly AI SRE
13. Rootly AI SRE
Its Rootly MCP server plugs directly into your IDE, allowing engineers to resolve incidents without leaving their code environment.
Teams aiming for "Self-Healing" systems where the goal is to automate the entire lifecycle from initial alert to final remediation.
Free trial. Starting from $20 / user / month. Custom enterprise pricing is also available.

Pros
- Covers the full incident lifecycle from detection through coordination to retrospective analytics, all in one platform with no stitching required
- IDE integration via MCP server lets engineers acknowledge, investigate, and resolve without leaving their code environment
- $20/user/month entry point makes it accessible to teams of all sizes
Cons
- Incident coordination and workflow automation are stronger than causal RCA. Teams whose main bottleneck is finding the root cause may need an additional investigation layer
- Works best in Slack-native environments. Teams on Microsoft Teams or other communication tools have a less seamless experience
- Autonomous remediation capabilities are less mature than platforms like Resolve.ai that were built autonomous-first from day one
 14. Harness AI SRE
14. Harness AI SRE
Harness is a full software delivery platform valued at $5.5B that has extended its AI capabilities into incident response through its AI SRE suite. Its standout feature is the Human-Aware Change Agent, which listens to live conversations in Slack, Teams, and Zoom during an incident and connects the human signals from those conversations to the actual deployment changes that caused the problem.
Harness builds a Software Delivery Knowledge Graph that maps code changes, deployments, feature flags, configuration, and infrastructure all in one place. When an incident fires, the AI correlates it against this graph rather than just telemetry, making it far easier to trace an incident back to a specific change.
Engineering teams that already use Harness for CI/CD and want AI-assisted incident response natively connected to their deployment pipeline, without introducing a separate tool.
Custom pricing

Pros
- Unique Human-Aware Change Agent connects conversational signals from Slack, Zoom, and Teams directly to deployment changes, capturing context that purely telemetry-based tools miss
- Deeply integrated across the full software delivery lifecycle, so incident context is automatically tied to the change that caused it
- Strong enterprise compliance posture with RBAC, audit trails, and policy-aware AI built in from the start
Cons
- AI SRE capabilities are most valuable if you are already using Harness for CI/CD. Teams on other delivery pipelines get significantly less out of it
- Platform breadth can feel overwhelming: Harness covers CI/CD, feature flags, chaos engineering, and cost management, which makes it harder to adopt narrowly for SRE alone
- No transparent AI SRE-specific pricing, and the overall platform investment needed to unlock full value is substantial
Cloud-Native AI SRE
 15. AWS DevOps Agent
15. AWS DevOps Agent
Best suited for teams already operating within AWS who want native AI-driven operations without introducing third-party tools.
AWS DevOps Agent is Amazon's purpose-built AI SRE product, now generally available. It investigates incidents by correlating telemetry, code, and deployment data across your stack. It works alongside tools your team already uses, including CloudWatch, Datadog, Dynatrace, New Relic, Splunk, GitHub, GitLab, and your incident response stack.
The agent is built on top of AWS's own infrastructure access patterns, which gives it significantly faster querying across AWS datasets than a generic LLM wrapper sitting on top of the same data. It also learns from how your team investigates incidents over time, building skills that carry forward to future incidents of the same type.
Teams running primarily on AWS who want a native AI SRE option without bringing in a third-party vendor.
$0.0083 per agent-second. Free 2-month trial available.

Pros
- Early results from preview customers are strong: 75% lower MTTR, 80% faster investigations, and 94% root cause accuracy
- Despite the name, it works across AWS, Azure, and on-premises environments via MCP
- Builds learned skills from past investigations, so the same class of incident gets faster to resolve over time
Cons
- No public pricing, so you cannot assess cost until you are in a conversation with AWS sales
- Teams on GCP or in heavily multi-cloud environments will get less value from the tight AWS-native integration
- Just hit GA, so the long-term track record at enterprise scale is still being built out
Comparison Table: Top AI SRE Tools in 2026
| Tool | AI Approach | Root Cause Analysis | Auto-Remediation | Best For | Kubernetes Support | OTel Native | Pricing |
|---|---|---|---|---|---|---|---|
| Sherlocks AI | LLM + 16 domain-specialized agents | Strong, awareness graph links telemetry with historical incidents | Remediation recommendations with human approval | Teams with siloed knowledge and recurring incidents | Yes, dedicated Kubernetes Sherlock agent | Yes | From $1,500/month |
| Resolve.ai | Multi-agent LLM with parallel investigation | Strong, cross-stack RCA across code, infra, and telemetry | Suggested fixes with mandatory human approval | Fortune 500 teams automating Level 1 on-call toil | Yes, full infra coverage including K8s | Partial | $1M+/year |
| Traversal | Causal reasoning engine | Strong, purpose-built causal RCA for distributed dependency chains | Investigation only, no automated remediation | Large microservice meshes with cascading failures | Yes, designed for distributed cloud-native systems | Not disclosed | Not available |
| Neubird (Hawkeye) | LLM layer on existing monitoring tools | Moderate, limited by your existing observability setup | Guided suggestions, not autonomous execution | Hybrid and multi-cloud enterprises mid-migration | Partial, via existing monitoring integrations | Partial | From $15/investigation |
| Deductive.ai | Knowledge graph + LLM reasoning | Strong, links application logic to real-time system behavior | Limited, focused on investigation and explanation | Data-heavy teams with complex pipelines | Partial | Not disclosed | Not available |
| Lightrun AI SRE | Runtime context engine with live instrumentation | Strong, proves root cause against live execution data, not static telemetry | Runtime-validated fixes and automated remediation suggestions | Teams debugging AI-generated code and unknown unknowns | Yes, live runtime context across containerized environments | Partial | Not available |
| Komodor (Klaudia AI) | Kubernetes-specialist agents trained on production telemetry | Strong, 95% accuracy on Kubernetes-specific failures | Autonomous self-healing with configurable human-in-the-loop guardrails | Platform teams running large-scale Kubernetes at enterprise | Yes, Kubernetes only, best-in-class | Partial | Custom pricing |
| Datadog (Bits AI SRE) | LLM add-on within Datadog platform | Moderate, best within Datadog telemetry, limited outside it | Workflow suggestions only, no autonomous execution | Teams fully committed to the Datadog ecosystem | Yes, native Kubernetes monitoring and analysis | Yes | $500 per 20 investigations |
| Metoro | eBPF kernel-level telemetry + LLM reasoning | Strong, complete eBPF context enables cleaner causal RCA | Deployment verification and remediation suggestions with evidence | Kubernetes teams wanting zero instrumentation overhead | Yes, Kubernetes only, eBPF-native | Yes (OTel + eBPF) | Free; $20/node/month |
| Middleware OpsAI | Agentic AI built on first-party observability stack | Strong, full-stack correlation across backend, frontend, and telemetry down to the line of code | Configurable: Auto RCA (proposes a PR) or Auto Fix (applies the fix directly) | Teams wanting deep, native AI remediation on a unified observability stack | Yes, deep integration via first-party telemetry | Yes | Usage-based, free 14-day trial |
| Agent0 (by Dash0) | Federated specialist agents, OTel-native | Strong, transparent step-by-step causal reasoning with full evidence trail | Remediation suggestions, portable PromQL queries generated | Teams wanting open-standards AI with zero vendor lock-in | Yes, native OTel Kubernetes support | Yes, 100% | From $50/month |
| Dynatrace (Davis AI) | Hypermodal AI, predictive + causal + generative combined | Very strong, deterministic causal AI using Smartscape topology and Grail lakehouse | Automated remediation workflows with governance controls | Large enterprises needing full-stack observability and AI SRE | Yes, deep Kubernetes and multi-cloud support | Yes | From $58/month per 8 GiB host |
| Rootly AI SRE | LLM-native incident management platform | Moderate, stronger on coordination than deep causal investigation | Full lifecycle automation from alert to retrospective via MCP | Teams automating the entire incident lifecycle end to end | Yes, Kubernetes alert routing and triage supported | Yes | From $20/user/month |
| Harness AI SRE | Knowledge graph + LLM with human conversation analysis | Strong, correlates deployment changes with human signals from Slack and Zoom | Automated rollbacks and deployment verification with guardrails | Teams already on Harness CI/CD wanting native incident response | Yes, deep Kubernetes deployment and rollback integration | Yes | Custom pricing |
| AWS DevOps Agent | Agentic AI with AWS-native telemetry correlation | Strong: 94% root cause accuracy in preview, learned skills improve over time | Autonomous investigation with human-approved remediation | Cloud-native teams in the AWS ecosystem wanting native AI SRE without third-party tools | Yes, deep AWS EKS and container support | Partial, works with OTel via integrations | $0.0083/agent-second; free 2-month trial |
Are There Open Source AI SRE Options?
Yes, but the honest answer is that no single open source project gives you what the commercial tools above do out of the box. What you get instead is a set of components you assemble and maintain yourself.
Most teams start with Prometheus for metrics, Grafana for visualization and alerting, and OpenTelemetry for collecting logs, metrics, and traces without locking into a specific vendor. SigNoz sits on top of that as an open source alternative to Datadog, bringing all three signals into one interface with an AI layer that is still maturing.
The trade-off is straightforward. You keep full control of your data, avoid licensing costs, and stay vendor-neutral. In return, you take on the work of running, integrating, and maintaining all of it. Adding an actual AI reasoning layer on top, typically via OpenAI or an open source LLM, requires more engineering investment than most teams plan for upfront.
This approach works well for teams with strong platform engineering capacity, strict data residency requirements, or budget constraints that rule out commercial tools. If your main bottleneck is investigation speed rather than cost, a commercial tool will get you there faster. In practice, open source AI SRE works best for teams with strong platform engineering capabilities who prefer flexibility over out-of-the-box automation.
How We Evaluated These AI SRE Tools
We did not rely on vendor marketing pages or G2 reviews to build this list. As a team that builds and runs an AI SRE platform ourselves, we evaluated every tool the way a skeptical SRE would: by stress-testing the claims against real production scenarios.
Our evaluation criteria:
Causal depth, not just correlation. We looked at whether each tool could explain why something broke, not just flag that it did. Tools that surface symptoms without tracing to root cause scored lower regardless of how polished the interface was.
Honest autonomy claims. Several tools in this space market autonomous remediation but require significant manual setup to get there. We noted this gap where we found it.
Pricing transparency. Hidden pricing is a friction signal. We documented exactly what is publicly available and flagged where you need to go through a sales cycle just to get a number.
Integration realism. We asked: what does Day 1 actually look like? Tools that require months of instrumentation before delivering value were marked accordingly.
Kubernetes and cloud-native fit. Given that over 60% of SRE teams now run containerized workloads, we specifically evaluated each tool's depth on Kubernetes, not just whether it supports it.
We also drew on our own experience running Sherlocks AI across multiple customer environments, which gives us a ground-level view of where AI SRE tools succeed and where they fall short in practice. Where we had a direct conflict of interest, we applied stricter scrutiny to our own tool and gave Sherlocks AI the same honest cons treatment as every other platform on this list.
Last reviewed: Jul 1, 2026
How to Choose the Right AI SRE Tool
Identify Your Primary Operational Bottleneck
Before looking at tools, figure out where your team spends the most time during an incident. McKinsey research on AI operations shows that leading organizations achieve 3.8x better performance improvement than laggards when implementing AI in operations - making tool selection critical:
If you spot issues quickly but spend hours manually linking logs and traces to understand the "why," focus on tools that emphasize Reasoning and Root Cause Analysis.
If your main challenge is managing communication, updating stakeholders, and following runbooks, look for tools that highlight Orchestration and Guided Workflows.
Match the Tool to Your Architecture, Not Your Headcount
In 2026, the best tool depends on how complex your system is, regardless of your team size:
High-complexity setups suffer from "cascading failures." You need an AI with Causal Reasoning that can trace a request across different service boundaries.
Simpler architectures often have clearer failure points. In these instances, deep agentic "traversal" is unnecessary; Augmented Analysis tools that speed up data retrieval and summarization are more suitable.
Prioritize "Data Substrate" Readiness
AI performs best with the right data. Assess tools based on how they deal with your current stack:
Seek tools that work with your existing telemetry (OpenTelemetry, Prometheus, etc.) without requiring new, proprietary agents.
Ensure the tool can reason across billions of unique data points (like Request IDs or User IDs) without slowing down or becoming prohibitively costly.
Define Your Comfort Level with Autonomy
Clarify how much autonomy you want:
The AI conducts the investigation and presents a "narrative briefing" to the engineer, who then decides on the fix.
The AI is allowed to suggest and, with approval, carry out fixes (like rolling back a deployment or scaling a cluster).
Regardless of the model, the tool must provide Explainability, it should show the exact evidence trail used to reach its conclusion.
Evaluate Institutional Memory vs. Static Knowledge
The real test of an AI SRE tool comes during a repeat incident:
A 2026-ready tool shouldn't only look at real-time metrics; it should include your past post-mortems, Slack discussions, and Jira tickets.
You want a system that builds a "Knowledge Graph" of your specific environment. This allows it to spot patterns from months ago and surface the historical solution instantly.
The "Red Flag" Checklist
Avoid tools that:
- Hallucinate RCA without evidence
- Hide pricing behavior under load
- Require manual labeling to learn
Conclusion
In 2026, AI SRE will serve as the crucial link between human-scale thinking and the growing complexity of machine-generated codebases. Rather than posing a threat, these tools act as an "Iron Man suit" for engineers. They alleviate the burden of manual log analysis, allowing you to reclaim your position as a strategic architect.
We must embrace this change because AI provides the speed to investigate in parallel while humans deliver the causal intuition and ethical judgment that no model can replicate. Ultimately, collaborating with AI doesn't replace the SRE, it empowers you to lead a more resilient, autonomous ecosystem without the strain of traditional on-call work. To understand where this is all heading, explore our perspective on the future of AI-powered incident management and how it's transforming reliability engineering.
The shift is no longer just toward better observability. It is toward systems that can detect, diagnose, and resolve issues on their own.
Frequently Asked Questions
The best AI for SRE depends on your specific needs, but leading options in 2026 include Sherlocks AI for collaborative incident response, Resolve.ai for automated remediation workflows, and Traversal for complex distributed system analysis. The key is choosing an AI SRE that provides causal reasoning (not just metric correlation) and integrates seamlessly with your existing observability stack. Understanding what AI SRE addresses can help you evaluate which solution fits your team's operational bottlenecks best.
When choosing an SRE alerting tool that scales, prioritize three factors: high-cardinality data handling (can it process billions of unique metrics without degrading performance?), zero-reinstrumentation compatibility (does it work with existing telemetry like OpenTelemetry or Prometheus?), and intelligent alert grouping to prevent notification fatigue. The best tools use AI to automatically correlate related alerts and suppress noise, ensuring your on-call engineers receive actionable signals rather than alert storms.
Modern incident management platforms with AI SRE capabilities include PagerDuty (AI-powered noise reduction and response orchestration), Rootly AI SRE (automated workflow coordination), Incident.io (Slack-native with AI-assisted triage), and Sherlocks AI (contextual investigation and institutional memory). The future of SRE is moving toward AI-powered incident management that actively investigates root causes and suggests remediation steps based on historical context and real-time telemetry analysis.
The leading AI SRE tools in 2026 focus on agentic reasoning rather than simple automation. Top contenders include Sherlocks AI (collaborative knowledge retention), Resolve.ai (autonomous remediation), Traversal (causal analysis for distributed systems), Neubird Hawkeye (multi-cloud enterprise support), and Deductive.ai (knowledge graph-based investigation). Each tool excels in different scenarios: Sherlocks AI prevents knowledge silos, Traversal handles complex microservice dependencies, and Datadog Bits AI integrates natively with existing Datadog workflows.
For microservices architectures, the best alerting tools combine distributed tracing with context-aware correlation. Look for platforms that can trace requests across service boundaries, automatically map service dependencies, and use causal inference to distinguish between symptoms (like high latency) and root causes (like a resource lock in a downstream database). Tools like Traversal excel at navigating complex dependency chains, while platforms like Datadog and New Relic offer deep microservices observability.
AI SRE tools are particularly effective for incidents involving complex distributed systems, performance degradations, deployment-related failures, and recurring issues with known patterns. They excel at correlating signals across logs, metrics, and traces to identify root causes like resource contention, configuration drift, database locks, or cascading service failures. However, AI SRE works best as an "Iron Man suit" for engineers, handling parallel investigation and data analysis while humans provide strategic judgment for novel incidents or situations requiring business context.
An AI SRE is an intelligent system that uses large language models and reasoning engines to detect, investigate, and help resolve production incidents, essentially acting as a digital teammate rather than a replacement for human SREs. While human SREs provide strategic thinking, business context, and ethical judgment, AI SREs handle the toil: analyzing thousands of metrics simultaneously, correlating disparate signals, and surfacing historical incident patterns. Being an SRE is inherently chaotic, and AI SREs address that chaos by maintaining perfect memory of every incident and executing parallel investigations.
AI SRE tool pricing in 2026 varies significantly based on deployment scale and feature set. Entry-level options start around $50–500/month (Dash0 Agent0 at $50/month, Datadog Bits AI at $500 per 20 investigations), mid-tier solutions range from $1,500–20,000/month (Sherlocks AI starts at $1,500/month, PagerDuty at $799/month), while enterprise platforms can reach $1M+/year (Resolve.ai). Most vendors offer usage-based pricing, and the ROI typically comes from reducing MTTR and eliminating repetitive on-call toil.
Major observability platforms have integrated AI-assisted incident response capabilities: Datadog offers Bits AI SRE (natively integrated with Datadog telemetry), New Relic provides AI-powered anomaly detection, and traditional monitoring tools increasingly partner with specialized AI SRE platforms. However, purpose-built AI SRE tools like Sherlocks AI, Resolve.ai, and Deductive.ai often provide deeper reasoning capabilities because they are designed specifically for investigation rather than just data collection, with a focus on causal inference and contextual awareness.
Both are AI-native SRE platforms, but they take different approaches. Resolve AI focuses on AIOps with pattern detection, while Sherlocks AI uses LLM reasoning for natural language investigation. For a full breakdown of features, pricing, and use cases, check out our Resolve AI vs Sherlocks AI comparison.
Claude Code is a development tool for writing code and automating git workflows. AI SRE platforms like Sherlocks AI are operational tools for detecting incidents and investigating root causes in production. Many teams use both: Claude Code for development, Sherlocks AI for operations. Read our detailed comparison to see which tool fits your workflow.
Start by identifying your biggest bottleneck, detection, investigation, or coordination. If incidents are hard to find, prioritize an observability layer like Datadog or Grafana first. Once you have signal coverage, layer in an AI SRE tool like Sherlocks AI to handle investigation and root cause analysis on top of that existing telemetry.
AIOps is the broader category, it covers using AI across all IT operations including infrastructure management, event correlation, and capacity planning. AI SRE is a narrower, more focused discipline that applies AI specifically to production reliability: detecting incidents, investigating root causes, and reducing MTTR. Think of AIOps as the umbrella and AI SRE as the sharpest tool inside it.
Not necessarily. Tools like Datadog and Dynatrace already include AI for monitoring and alerts, but AI-native SRE tools go further into automated debugging and remediation. The need depends on how much automation vs visibility your team requires.
No, AI SRE tools are designed to augment, not replace, human SREs. They help with detection, triage, and initial diagnosis, but humans are still needed for complex decision-making, system design, and handling edge cases.
Related Reading
PagerDuty vs New Relic vs Datadog vs Sherlocks AI
Tested on the same production incident. See which platform found the root cause fastest.
Best Incident Response Platforms for DevOps (2026)
The four-layer IR stack framework and how to choose tools for each layer.
Claude Code vs. Sherlocks AI
Can a general-purpose AI agent replace a dedicated AI SRE platform? An honest comparison.
Vibe SRE vs Agentic SRE
Why how you use AI for SRE matters more than which model you choose.
Upgrade Your SRE Stack Today
Stop wasting time on manual correlation and tool sprawl. See how Sherlocks AI turns fragmented signals into actionable insights in minutes.
Book a Demo